#Apache Spark AWS Lambda Executor (SAMBA)
SAMBA is an Apache Spark package offering seamless integration with the AWS Lambda compute service for Spark batch and streaming applications on the JVM. This library is built on top of the aws-gateway-executor library, a lightweight Java client library for calling APIs exposed by the AWS API Gateway.
Within traditional Spark deployments RDD tasks are executed using fixed compute resources on worker nodes within the Spark cluster. With SAMBA, application developers can delegate selected RDD tasks to execute using on-demand AWS Lambda compute infrastructure in the cloud.
More generally, SAMBA also provides a simple yet powerful mechanism for Spark applications to integrate with general REST services exposed on the AWS API Gateway.
A number of example applications are provided to demonstrate the use of the SAMBA library to deliver RDD task delegation and REST integration.
libraryDependencies += "io.onetapbeyond" %% "lambda-spark-executor_2.10" % "1.0"
compile 'io.onetapbeyond:lambda-spark-executor_2.10:1.0'
Include the SAMBA package in your Spark application using spark-shell, or spark-submit. For example:
$SPARK_HOME/bin/spark-shell --packages io.onetapbeyond:lambda-spark-executor_2.10:1.0
This library exposes a new delegate transformation on Spark RDDs of type
RDD[AWSTask]. The following sections demonstrate how to use this new
RDD operation to leverage AWS Lambda compute services directly within
Spark batch and streaming applications on the JVM.
See the documentation
on the underlying aws-gateway-executor library for details on building
AWSTask and handling AWSResult.
For this example we assume an input dataRDD, then transform it to generate
an RDD of type RDD[AWSTask]. In this example each AWSTask will
invoke a sample AWS Lambda score computation when the RDD is eventually
evaluated.
import io.onetapbeyond.lambda.spark.executor.Gateway._
import io.onetapbeyond.aws.gateway.executor._
val aTaskRDD = dataRDD.map(data => {
AWS.Task(gateway)
.resource("/score")
.input(data.asInput())
.post()
})
The set of AWSTask within aTaskRDD can be scheduled for
processing on AWS Lambda infrastructure by calling the new delegate
operation provided by SAMBA on the RDD:
val aResultRDD = aTaskRDD.delegate
When aTaskRDD.delegate is evaluated by Spark the resultant aResultRDD
is of type RDD[AWSResult]. The result returned by the sample score
computation on the original AWSTask is available
within these AWSResult. These values can be optionally cached, further
processed or persisted per the needs of your Spark application.
Note, the use here of the AWS Lambda score function is simply
representative of any computation made available by the AWS API Gateway.
For this example we assume an input stream dataStream, then transform
it to generate a new stream with underlying RDDs of type RDD[AWSTask].
In this example each AWSTask will execute a sample AWS Lambda score
computation when the stream is eventually evaluated.
import io.onetapbeyond.lambda.spark.executor.Gateway._
import io.onetapbeyond.aws.gateway.executor._
val aTaskStream = dataStream.transform(rdd => {
rdd.map(data => {
AWS.Task(gateway)
.resource("/score")
.input(data.asInput())
.post()
})
})
The set of AWSTask within aTaskRDD can be scheduled for
processing on AWS Lambda infrastructure by calling the new delegate
operation provided by SAMBA on each RDD within the stream:
val aResultStream = aTaskStream.transform(rdd => rdd.delegate)
When aTaskStream.transform is evaluated by Spark the resultant
aResultStream has underlying RDDs of type RDD[AWSResult]. The result
returned by the sample score computation on the original AWSTask is
available within these AWSResult. These values can be optionally cached,
further processed or persisted per the needs of your Spark application.
Note, the use here of the AWS Lambda score function is simply
representative of any computation made available by the AWS API Gateway.
###SAMBA Spark Deployments
To understand how SAMBA delivers the computing power of AWS Lambda to Spark applications on the JVM the following sections compare and constrast the deployment of traditional Scala, Java, and Python applications with Spark applications powered by the SAMBA library.
####1. Traditional Scala | Java | Python Spark Application Deployment
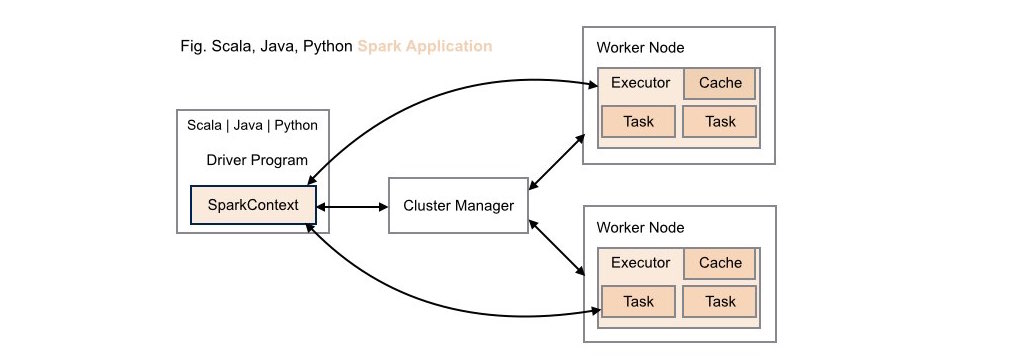
Without SAMBA library support, traditional task computations execute locally on worker nodes within the cluster, sharing and therefore possibly constrained by, the resources available on each worker node.
####2. Scala | Java + AWS Lambda (SAMBA) Spark Application Deployment
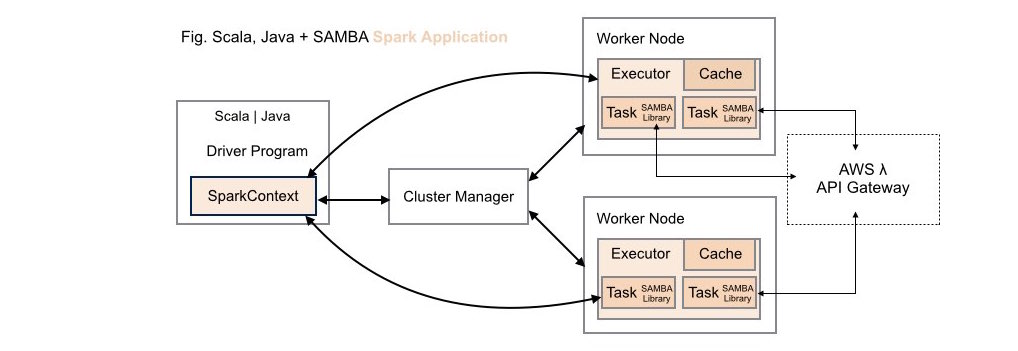
SAMBA powered Spark applications benefit from the following enhancements:
-
RDD tasks can be delegated to execute on AWS Lambda compute infrastructure in the cloud.
-
Driver programs can easily integrate with general REST services exposed on the AWS API Gateway.
For certain application workflows and workloads Spark task delegation to
AWS Lambda compute infrastructure will make sense. However,
it is worth noting that this library is provided to extend-not-replace the
traditional Spark computation model, so I recommend using SAMBA judiciously.
See the LICENSE file for license rights and limitations (Apache License 2.0).